Command Line on OS X and Linux
Command Line on Windows
Python
Javascript
R Language
Ruby
Excel Macros
API
Geodict
Text to Places
IP Address to Coordinates
Street Address to Coordinates
Google-style geocoder
Coordinates to Politics
File to Text
Text to Sentences
HTML to Text
HTML to Story
Text to People
Text to Times
Text to Sentiment
Coordinates to Statistics
TwoFishes Geocoder
Setting up your own server
Amazon EC2
Vagrant
Questions? Get help from http://groups.google.com/group/dstk-users
Usage
Command Line on OS X and Linux
Download python_tools.zip, extract into a new folder, cd into it and run ./install
This will create a set of scripts you can run directly from the command line, like this:
html2text http://nytimes.com | text2people
The command above fetches the New York Times front page, extracts a plain text version, and then pulls out likely names. There's command-line scripts for all the API calls, and they're designed to work according to the normal Unix conventions. That means you can pipe the output from one command to another, since if no inputs are specified the commands will read from stdin. The calls that take in large chunks of text interpret any arguments as file names or URLs to read. If a name starts with "http://" the document at that location will be fetched and processed, as in the New York Times example above. If a file name is a directory, it will recurse down through the folder structure, reading in all files it finds. For example:
file2text -h ~/scanned_documents/*.jpg > scanned_text.txt
This will run OCR on all the JPEG images in that folder (the same command also works on PDF, DOC and XLS files). The -h switch is applicable to most commands, and tells them to output header information, in this case the file name for each chunk of text pulled from an image.
Commands that take in inputs that aren't natural-language text or html treat their arguments as the strings to process, rather than file names. For example, this call looks up the given IP address, not the file with that name:
ip2coordinates "67.169.73.113"
If you do want to run one of these commands on a large number of inputs, you can pipe them in from a file on stdin, and each line in the file will be treated as an input:
ip2coordinates < someips.txt
The commands that produce structured results (something other than a blob of text) write out their information in comma-separated value format. This means you can redirect their output into a .csv file and then load that into your favorite spreadsheet, or read it into your own scripts to do custom processing. Here's an example of how that works:
text2places -h http://nytimes.com/ > nytimes_places.csv
By default, the command-line tools will use the datasciencetoolkit.org server to do the processing, but if you set up your own server you can redirect all calls to that URL by setting the enviroment variable DSTK_API_BASE or using the -a switch for each command, eg:
export DSTK_API_BASE=http://example.com
Command Line on Windows
Because Windows doesn't come with Python installed by default, you'll need to go through a few extra steps:
Go to http://www.python.org/download/releases/ and follow the link starting with 2.6 (for example in April 2011, that's 2.6.6).
Click on the "Windows x86 MSI Installer" link. (If you're technically savvy, and know you have a 64 bit PC, you can choose "Windows X86-64 MSI Installer", but if you're in doubt, stick with the standard one.)
The file should now be downloading. Once it has finished, run it and an installer should start up. Click "Next" to choose the default options, and then end with "Finish" once it's done.
Open up a DOS prompt by going to "All Programs"->"Accessories"->"Command Prompt" from the Start Menu.
Type the command below to make sure Python has been installed.
C:\Python26\python.exe
If it works, you'll see some text followed by a prompt. Type the command exit() to leave this mode.

Download python_tools.zip, extract into a new folder and cd into it from the DOS prompt.
On my machine the default location is C:\Users\Administrators\Downloads\python_tools.zip, I can unzip it by double-clicking that archive in the file view and selecting "Extract All Files", and then to enter the new directory I type cd C:\Users\Administrators\Downloads\python_tools into the DOS prompt. The exact directories will vary depending on your user name and which version of Windows you're running.
To make sure the Toolkit interface was installed correctly, run this command:
C:\Python26\python.exe python\dstk.py
You should see a help message appear showing the options that you can pass into the script.
To run something useful, you need to put the name of the command you want at the end of this, along with some data to analyze. For example, you could retrieve information about an IP address like this:
C:\Python26\python.exe python\dstk.py ip2coordinates 67.169.73.113
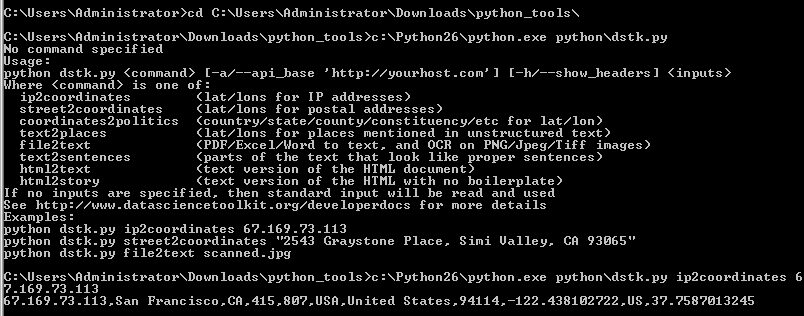
You can now run all of the commands as described in the Unix section, by adding the C:\Python26\python.exe python\dstk.py part at the start of each line. You can get rid of that extra typing by adding Python to your command path and installing Cygwin, but that's not required.
Python
A package is available on PyPi so you can run pip install dstk, or you can manually download python_tools.zip, extract into a new folder, cd into it and run python setup.py
This installs the DSTK interface as a module. If you run the Python interactive console, you can test it out:
>>> import dstk
>>> dstk = dstk.DSTK()
>>> dstk.street2coordinates('2543 Graystone Place, Simi Valley, CA 93065')
{'2543 Graystone Place, Simi Valley, CA 93065': {'confidence': 0.92200000000000004, 'street_number': '2543', 'locality': 'Simi Valley', 'street_name': 'Graystone Pl', 'fips_county': '06111', 'country_code3': 'USA', 'country_name': 'United States', 'longitude': -118.76620699999999, 'country_code': 'US', 'latitude': 34.280873999999997, 'region': 'CA', 'street_address': '2543 Graystone Pl'}}
You can access all of the API methods by calling the corresponding function on the interface object. Most functions can take either a single string, or an array of input strings, and return either an array or dictionary of results. The individual methods' documentation explains the exact format of their output.
By default, the datasciencetoolkit.org server is called, but if the DSTK_API_BASE environment variable is set, that URL will be used instead. You can also pass in a custom server URL in the options structure when you create the interface object:
dstk = dstk.DSTK({'apiBase':'http://example.com'})
If no Data Science Toolkit server is detected at the URL, an exception is thrown. You can skip the call required to pull the server information by setting checkVersion to False in the constructor options.
For a full example of the Python interface in action, look at the command-line tool included at the bottom of the dstk.py file inside python_tools.zip.
Javascript
The Javascript interface is available as a jQuery plugin, to get started download jquery.dstk.js. Once you've included that in your page, you'll be able to call it like this:
var dstk = $.DSTK();
dstk.ip2coordinates('67.169.73.113', function(result) {
if (typeof result['error'] !== 'undefined') {
alert('Error: '+result['error']);
return
}
for (var ip in result) {
var info = result[ip];
alert(ip+' is at '+info['latitude']+','+info['longitude']);
}
});
The DSTK interface object supports all of the API calls except file2text, since there's no simple way to upload files directly from Javascript. It uses JSONP calls where possible, injecting script tags to allow cross-domain access, so scripts on your own sites' pages can run using the default datasciencetoolkit.org server. Since JSONP relies on the GET method, it runs into URL size limits when dealing with larger text inputs (over about 8k). It will automatically switch to using jQuery's AJAX POST method, but this will fail if you're running cross-domain. You can work around this by setting up a proxy on your own domain, either a full copy of the server or a proxy pointing to the datasciencetoolkit.org site. You specify which server to use by setting the apiBase option in the constructor, eg:
var dstk = $.DSTK({apiBase:'http://example.com'});
R Language
You can use the toolkit from R by grabbing the package from CRAN. Big thanks go to Ryan Elmore and Andrew Heiss for putting this together.
To use it, just run require('RDSTK') and then one of the functions corresponding to an API name, eg
coordinates2statistics(37.769456, -122.429128, 'population_density')
text2sentiment("I love this hotel!")
Ruby
Install the gem using gem install dstk and then create an instance of the client like this:
dstk = DSTK::DSTK.new
Then you can call functions corresponding to an API name, eg
dstk.coordinates2statistics([37.769456, -122.429128], 'population_density')
dstk.text2sentiment('I love this hotel!')
Thanks go to Cam Peterson for coding help on this gem.
Excel Macros
You can use the geocoding functions from Excel by installing this VBA file from github. Thanks to Luke Peterson for creating this.
Feed a USA street address to getGeocode() to get an API response, which you can pass through getLatitude() and getLongitude() in order to put the Long/Lat into separate columns. Best-practice is to pull the API response into a single field with getGeocode(), then parse that field with getLatitude() and getLongitude(), rather than using getLatitude(getGeocode([Address])) and getLongitude(getGeocode([Address])), since the latter will double the number of requests to the dstk server.
API
Geodict
As an emulation of Yahoo's service, a good place to start is their Placemaker documentation. There's also concrete examples of how to call the Placemaker API in the test_suite folder, and for Javascript in the source of the home page of this server. I've focused on supporting the most commonly used features of Yahoo's interface, so if you have some code that relies on something that's missing, email me a sample of your source and I'll do my best to add that in.
Here's how the Ushahidi Swift project calls Placemaker to pull the first location mentioned in a document.
For the original Yahoo API:
define('BASE_URL', 'http://wherein.yahooapis.com/');
define('APP_ID', '<Their API Key>');
Using GeodictAPI:
define('BASE_URL', 'http://www.datasciencetoolkit.org/');
define('APP_ID', ''); // No API key needed
Code for calling the API and parsing the results:
$encodedLocation = \urlencode($location);
$url = BASE_URL."v1/document";
$postvars = "documentContent=$encodedLocation&documentType=text/plain&appid=$appid";
$return = curl_request($url, $postvars);
$xml = new \SimpleXMLElement($return);
$long = (float) $xml->document->placeDetails->place->centroid->longitude;
$latt = (float) $xml->document->placeDetails->place->centroid->latitude;
The results will differ between the two APIs, as the algorithms are quite different. In particular, I designed Geodict for applications that are intolerant of false positives, so for example Placemaker will flag "New York Times" as a location whereas Geodict will ignore it.
Text to Places
This is the friendly interface to the same underlying functionality as Geodict. It uses a much simpler JSON format, taking an array with a single string as its input and returning an array of the locations found in that text. Here's an example:
curl "http://www.datasciencetoolkit.org/text2places/%5b%22Cairo%2c+Egypt%22%5d"
[{"type":"CITY","start_index":"0","end_index":"4","matched_string":"Cairo, Egypt",
"latitude":"30.05","longitude":"31.25","name":"Cairo"}]
IP Address to Coordinates
This API takes either a single numerical IP address, a comma-separated list, or a JSON-encoded array of addresses, and returns a JSON object with a key for every IP. The value for each key is either null if no information was found for the address, or an object containing location information, including country, region, city and latitude/longitude coordinates. Here's an example:
{"67.169.73.113":{
"country_name":"United States",
"area_code":415,
"region":"CA",
"postal_code":"94114",
"city":"San Francisco",
"latitude":37.7587013244629,
"country_code":"US",
"longitude":-122.438102722168,
"country_code3":"USA",
"dma_code":807}};
To call the API, you can make either a GET or a POST request to /ip2coordinates. If you make a GET request, then you need to pass in the IP addresses in the suffix of the URL, eg /ip2coordinates/130.12.1.34%2C67.169.73.113.
Using GET you can also pass in a callback parameter in the URL, making it possible to run this as a JSONP cross-domain request. You can see this method in action if you view source on the home page of this server.
You can also make a POST request passing in the IP addresses in the body of the request. This is useful if you have very large arrays of IP addresses you need to process, since you won't hit any URL size limits.
This API uses data from http://www.maxmind.com/.
Street Address to Coordinates
This API takes either a single string representing a postal address, or a JSON-encoded array of addresses, and returns a JSON object with a key for every address. The value for each key is either null if no information was found for the address, or an object containing location information, including country, region, city and latitude/longitude coordinates. Here's an example:
curl "http://www.datasciencetoolkit.org/street2coordinates/2543+Graystone+Place%2c+Simi+Valley%2c+CA+93065"
{"2543 Graystone Place, Simi Valley, CA 93065":{
"street_name":"Graystone Pl",
"country_code":"US",
"latitude":34.280874,
"street_address":"2543 Graystone Pl",
"country_code3":"USA",
"fips_county":"06111",
"longitude":-118.766207,
"country_name":"United States",
"confidence":0.922,
"region":"CA",
"street_number":"2543",
"locality":"Simi Valley"}}
To call the API, you can make either a GET or a POST request to /street2coordinates. If you make a GET request, then you need to pass in the addresses in the suffix of the URL, as above.
Using GET you can also pass in a callback parameter in the URL, making it possible to run this as a JSONP cross-domain request. You can see this method in action if you view source on the home page of this server.
You can also make a POST request passing in the addresses in the body of the request. This is useful if you have very large arrays of addresses you need to process, since you won't hit any URL size limits. You pass them in as a JSON string, eg ["2543 Graystone Place, Simi Valley, CA 93065", "400 Duboce Ave, San Francisco, CA 94114"]
curl -X POST --data '["2543 Graystone Place, Simi Valley, CA 93065", "400 Duboce Ave, San Francisco, CA 94114"]' 'http://www.datasciencetoolkit.org/street2coordinates'
This API uses data from the US Census and OpenStreetMap, along with code from GeoIQ and Schuyler Erle.
Google-style geocoder
This emulates Google's geocoding API. It's designed to take the same arguments and return the same data structure as their service, to make it easy to port existing code. It's very similar in functionality to street2coordinates, taking a string representing a place or address, and converting it into structured data about the position of that location. Here's an example:
curl "http://www.datasciencetoolkit.org/maps/api/geocode/json?sensor=false&address=1600+Amphitheatre+Parkway,+Mountain+View,+CA"
{"results": [{
"types": ["street_address"],
"formatted_address": "1600 Amphitheatre Parkway, Mountain View, CA",
"geometry": {
"location": {"lat": 37.42382, "lng": -122.08999},
"location_type": "ROOFTOP",
"viewport": {
"southwest": {"lat": 37.42282, "lng": -122.09099},
"northeast": {"lat": 37.42482, "lng": -122.08899} }},
"address_components":[{"types": ["street_number"],"long_name": "1600","short_name": "1600"},
{"types": ["route"],"long_name": "Amphitheatre Pkwy","short_name": "Amphitheatre Pkwy"},
{"types": ["locality","political"],"long_name": "Mountain View","short_name": "Mountain View"},
{"types": ["administrative_area_level_1","political"],"long_name": "CA","short_name": "CA"},
{"types": ["country","political"],"long_name": "United States","short_name": "US"}]}],
"status": "OK"}
To call the API, you can make a GET request to /maps/api/geocode/json. You pass in the address you're querying for as a parameter in the URL as shown above. Other parameters that Google requires (like sensor or your API key) are accepted but ignored.
You can pass in a callback parameter in the URL, making it possible to run this as a JSONP cross-domain request. You can see this method in action if you view source on the home page of this server.
Reverse geocoding (getting information about what's located at particular coordinates) and XML output formats are not supported.
This API uses data from the US Census and OpenStreetMap, along with code from GeoIQ andSchuyler Erle.
Coordinates to Politics
This API takes either a single string representing a comma-separated pair of latitude/longitude coordinates, or a JSON-encoded array of objects containing two keys, one for latitude and one for longitude. It returns a JSON array containing an object for every input location. The location member holds the coordinates that were queried, and politics holds an array of countries, states, provinces, cities, constituencies and neighborhoods that the point lies within. Here's an example:
curl "http://www.datasciencetoolkit.org/coordinates2politics/37.769456%2c-122.429128"
[{"location":{"latitude":"37.769456","longitude":"-122.429128"},"politics":[
{"type":"admin2","code":"usa","friendly_type":"country","name":"United States"},
{"type":"admin4","code":"us06","friendly_type":"state","name":"California"},
{"type":"admin6","code":"06_075","friendly_type":"county","name":"San Francisco"},
{"type":"admin5","code":"06_67000","friendly_type":"city","name":"San Francisco"},
{"type":"constituency","code":"06_08","friendly_type":"constituency","name":"Eighth district, CA"}]}]
To combat errors caused by lack of precision, there's a small amount of fuzziness built into the algorithm, so that points that lie very close to borders get information on both possible areas they could be within.
To call the API, you can make either a GET or a POST request to /coordinates2politics. If you make a GET request, then you need to pass in the locations in the suffix of the URL, as above.
Using GET you can also pass in a callback parameter in the URL, making it possible to run this as a JSONP cross-domain request. You can see this method in action if you view source on the home page of this server.
You can also make a POST request passing in the locations in the body of the request. This is useful if you have very large arrays of locations you need to process, since you won't hit any URL size limits.
This API relies on data gathered by volunteers around the world for OpenHeatMap, along with US census information and neighborhood maps from Zillow.
File to Text
If you pass in an image, this API will run an optical character recognition algorithm to extract any words or sentences it can from the picture. If you upload a PDF file, Word document, Excel spreadsheet or HTML file, it will return a plain text version of the content. Unlike most of the calls, this one takes its input in the standard multipart form-encoded format that's used when browsers upload files, rather than as JSON. It returns any content it finds as a stream of text.
curl --form inputfile=@ExecutiveSummary.docx "http://www.datasciencetoolkit.org/file2text"
OverviewMoveableCode, inc. is a seed stage company funded by a National Science Foundation Phase 1 SBIR grant. The company is developing software applications for mobile devices with a particular emphasis on Augmented Reality (AR).
This API relies on the Ocropus project for handling images, and catdoc for pre-XML Word and Excel documents.
Text to Sentences
This call takes some text, and returns any fragments of it that look like proper sentences organized into paragraphs. It's most useful for taking documents that may be full of uninteresting boilerplate like headings and captions, and returning only the descriptive passages for further analysis.
curl -d "*Does*not*look_like999A sentence." "http://www.datasciencetoolkit.org/text2sentences"
{"sentences":""}
curl -d "But this does, it contains enough words. So does this one, it appears correct. This is long and complete enough too." "http://www.datasciencetoolkit.org/text2sentences"
{"sentences":"But this does, it contains enough words. So does this one, it appears correct. This is long and complete enough too. \n"}
The GET form of this call takes a JSON-encoded array of a single string containing the text to analyze. This string must be less than about 8,000 characters long, or the URL size limit will be exceeded. The Javascript interface automatically switches to POST for long text requests, which means they will not work cross-domain.
The POST form takes the input text as a single raw string in the body of the request. The result is a JSON-encoded object with a "sentences" member containing the matching parts of the input.
HTML to Text
This call takes an HTML document, and analyzes it to determine what text would be displayed when it is rendered. This includes all headers, ads and other boilerplate. If you want only the main body text (for example the story section in a news article) then you should use html2story on the HTML.
curl -d "<html><head><title>MyTitle</title></head><body><script type="text/javascript">something();</script><div>Some actual text</div></body></html>" "http://www.datasciencetoolkit.org/html2text"
{"text":"Some actual text\n"}
The GET form of this call takes a JSON-encoded array of a single string containing the text to analyze. This string must be less than about 8,000 characters long, or the URL size limit will be exceeded. The Javascript interface automatically switches to POST for long text requests, which means they will not work cross-domain.
The POST form takes the input text as a single raw string in the body of the request. The result is a JSON-encoded object with a "text" member containing the matching parts of the input.
This API relies on the Hpricot library to parse the HTML.
HTML to Story
This call takes an HTML document, and extracts the sections of text that appear to be the main body of a news story, or more generally the long, descriptive passages in any page. This is especially useful when you want to run an analysis only on the unique content of each page, ignoring all the repeated navigation elements.
curl -d "The contents of a real page" "http://www.datasciencetoolkit.org/html2story"
{"story":"The story text"}
This one is tough to demonstrate in a succinct example, because it requires a non-trivial document before it will accept its contents as a valid story.
The GET form of this call takes a JSON-encoded array of a single string containing the text to analyze. This string must be less than about 8,000 characters long, or the URL size limit will be exceeded. The Javascript interface automatically switches to POST for long text requests, which means they will not work cross-domain.
The POST form takes the input text as a single raw string in the body of the request. The result is a JSON-encoded object with a "story" member containing the matching parts of the input.
This API relies on the Boilerpipe library to recognize and extract the story text.
Text to People
Extracts any sequences of words that look like people's names, and tries to guess their gender, likely age, and ethnicity from the statistical properties of any names found. It's largely based on American surveys, and so works best on names that are common in English-speaking countries, though it does cover the most popular foreign-language names too. It also looks for some common titles like Mr and Mrs to help it spot possible people. It relies on capitalization of names, so it will only work on more formal texts.
There will inevitably be some noise (is "Will Hunting" in "Good Will Hunting" a name?) so you'll need an application where some false positives aren't a problem. For example, you could use this to spot the most popular people in a collection of crawled news pages.
curl -d "Tim O'Reilly, Archbishop Huxley" "http://www.datasciencetoolkit.org/text2people"
[{"first_name": "Tim",
"title": "",
"surnames": "O'Reilly",
"likely_age": 53,
"start_index": 0,
"end_index": 12,
"ethnicity": null,
"matched_string": "Tim O'Reilly",
"gender": "m"},
{"first_name": "",
"title": "archbishop",
"surnames": "Huxley",
"likely_age": null,
"start_index": 14,
"end_index": 31,
"ethnicity": { "percentage_of_total": 0.0002,
"percentage_hispanic": 0.0,
"percentage_white": 94.81,
"percentage_black": 0.0,
"percentage_asian_or_pacific_islander": 0.93,
"percentage_american_indian_or_alaska_native": 0.0,
"rank": 38587,
"percentage_two_or_more": 3.34},
"matched_string": "Archbishop Huxley",
"gender": "u"}]
The text is passed in either as a JSON-encoded array in the remainder of the URL for a GET call, or in the raw body of the request for POST. The usual 8,000 character limit on GET URLs applies, so use POST for larger texts.
This API uses my Ruby port of Eamon Daly and Jon Orwant's original GenderFromName Perl module to guess the gender of first names. It also uses information from the US Social Security Administration's analysis of baby names to guess both gender. The likely age guessing uses the baby names data, and actuarial tables from the NCHS to normalize for life expectancy.
The ethnicity breakdown of surnames is based on the US Census's list of all names that occurred 100 or more times in the 2000 survey.
Text to Times
Searches the input for strings that represent dates or times, and parses them into the standard form of a Ruby date/time string (eg "Mon Feb 01 11:00:00 -0800 2010") as well as seconds since Jan 1st 1970. It will attempt to guess the exact time for strings that are ambiguous, like "this Tuesday". Its guessing process is to look for a full date anywhere in the document, and calculate all relative times as offsets from the first date with a day, month and year it finds.
For example, if the text was an email with "Monday Feb 1st 2010" in the content, and there was a reference to "this Tuesday", the service would guess that meant Tuesday Feb 2nd 2010. If there are no full dates at all, then the current time and date will be used as the base. Any relative dates are marked as "is_relative" in the results. It also figures out the span of time that the string covers, and puts this in seconds as "duration" within each result.
It's designed to avoid false positives, at the cost of missing some strings that might represent dates. "I'm taking Computer Science 2010" won't be marked as the year 2010, since there's not enough evidence that it's really representing a time and isn't just a reference number.
curl -d "02/01/2010-Meeting this Wednesday" "http://www.datasciencetoolkit.org/text2times"
[{"start_index":1,"is_relative":false,"end_index":9,"time_seconds":1265011200.0,
"matched_string":"2/01/2010","time_string":"Mon Feb 01 00:00:00 -0800 2010",
"duration":86400},
{"start_index":19,"is_relative":true,"end_index":32,"time_seconds":1265184000.0,
"matched_string":"this Wednesday","time_string":"Wed Feb 03 00:00:00 -0800 2010",
"duration":86400}]
The text is passed in either as a JSON-encoded array in the remainder of the URL for a GET call, or in the raw body of the request for POST. The usual 8,000 character limit on GET URLs applies, so use POST for larger texts.
This API uses the Chronic Ruby gem to convert the strings it finds into times.
Text to Sentiment
Tries to guess whether the text represents a roughly positive or negative comment, and returns a score between -5 and 5. The lowest score indicates that there were words associated with unhappiness or dissatisfaction, a score of zero either means that no charged words were found, or that the positive and negative words balanced themselves out, and a high score shows that there were one or more 'good' words that occur in pleased, happy comments.
For example, "Great trip. Thanks for the warm welcome, Dallas and Fort Worth" gets a score of +2 because "great" has a weight of +3, and "warm" gives +1, so the average is +2.
It's using a very simple algorithm, based around Finn Årup's annotated list of words originally designed for analyzing the sentiment of Twitter messages. If you're diving deep into sentiment analysis, it's likely that you'll want to build your own algorithm trained for your particular domain, but Finn's list has proved very effective for everyday use.
curl -d "I hate this hotel" "http://www.datasciencetoolkit.org/text2sentiment"
{"score": -3.0},
The text is passed in either as a JSON-encoded array in the remainder of the URL for a GET call, or in the raw body of the request for POST. The usual 8,000 character limit on GET URLs applies, so use POST for larger texts.
This API uses Finn Årup's annotated list of words under an ODbL license.
Coordinates to Statistics
Returns characteristics like population density, elevation, climate, ethnic makeup, and other statistics for points all around the world at a 1km-squared or finer resolution.
By default it will return all of the statistics it can find for a given point, but you can narrow down the results by passing in a comma-separated list of the ones you want in the statistics URL parameter.
There are more statistics available for the US than other areas, and their names are prefixed by us_. There's a full list of all the statistics and their sources below.
The API takes either a single string representing a comma-separated pair of latitude/longitude coordinates, or a JSON-encoded array of objects containing two keys, one for latitude and one for longitude. It returns a JSON array containing an object for every input location. The location member holds the coordinates that were queried, and statistics holds a dictionary of all the information that was found. The value property holds the value of the statistic at that point, and the sourcename, description, and units properties describe it in more detail. If it's a proportion, the proportionof property tells you what other statistic it's a fraction of. Here's an example:
curl "http://www.datasciencetoolkit.org/coordinates2statistics/37.769456%2c-122.429128?statistics=population_density"
[{"location": {"latitude": 37.769456, "longitude": -122.429128},"statistics": {
"population_density": {
"description": "The number of inhabitants per square kilometer around this point.",
"value": 13543,
"source_name": "NASA Socioeconomic Data and Applications Center (SEDAC) – Hosted by CIESIN at Columbia University"
}}}]
To call the API, you can make either a GET or a POST request to /coordinates2politics. If you make a GET request, then you need to pass in the locations in the suffix of the URL, as above.
Using GET you can also pass in a callback parameter in the URL, making it possible to run this as a JSONP cross-domain request. You can see this method in action if you view source on the home page of this server.
You can also make a POST request passing in the locations in the body of the request. This is useful if you have very large arrays of locations you need to process, since you won't hit any URL size limits.
Here are the possible statistics:
- elevation - The height of the surface above sea level at this point. From the NASA and the CGIAR Consortium for Spatial Information .
- land_cover - What type of environment exists around this point - urban, water, vegetation, mountains, etc. From the European Commission Land Resource Management Unit Global Land Cover 2000 .
- mean_temperature - The mean monthly temperature at this point. From the WorldClim .
- population_density - The number of inhabitants per square kilometer around this point. From the NASA Socioeconomic Data and Applications Center (SEDAC) – Hosted by CIESIN at Columbia University .
- precipitation - The monthly average total precipitation at this point. From the WorldClim .
- us_households - The number of households in this area. From the US Census and the CGIAR Consortium for Spatial Information .
- us_households_linguistically_isolated - The proportion of households in which no one aged 14 or older speaks English very well From the US Census and the CGIAR Consortium for Spatial Information .
- us_households_single_mothers - The proportion of households with a female householder, no husband, and one or more children under eighteen. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units - The total number of housing units in this area From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_1950_to_1969 - The proportion of housing units built between 1950 and 1969. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_1970_to_1989 - The proportion of housing units built between 1970 and 1989. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_after_1990 - The proportion of housing units built after 1990. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_before_1950 - The proportion of housing units built before 1950. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_no_vehicle - The proportion of occupied housing units with no vehicle available. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_occupied - The proportion of housing units that are occupied. From the .
- us_housing_units_one_person - The proportion of housing units containing only one person From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_owner_occupied - The proportion of housing units that are occupied by their owners. From the US Census and the CGIAR Consortium for Spatial Information .
- us_housing_units_vacation - The number of vacant housing units that are used for seasonal, recreational, or occasional use. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population - The number of residents in this area From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_asian - The proportion of residents identifying as Asian. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_bachelors_degree - The proportion of residents whose maximum educational attainment was a bachelor's degree. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_black_or_african_american - The proportion of residents identifying as black or African American. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_black_or_african_american_not_hispanic - The proportion of residents who didn't identify as hispanic or latino, just black or African American alone From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_eighteen_to_twenty_four_years_old - The proportion of residents aged eighteen to twenty four years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_five_to_seventeen_years_old - The proportion of residents aged five to seventeen years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_foreign_born - The proportion of residents who were born in a different country. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_hispanic_or_latino - The proportion of residents who identify themselves as hispanic or latino. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_low_income - The proportion of residents who earn less than twice the poverty level From the .
- us_population_native_hawaiian_and_other_pacific_islander - The proportion of residents who identify as Native Hawaiian or other Pacific islander. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_one_to_four_years_olds - The proportion of residents aged one to four years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_over_seventy_nine_years_old - The proportion of residents over seventy nine years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_poverty - The proportion of residents whose income is below the poverty level From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_severe_poverty - The proportion of residents whose income is below half the poverty level. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_sixty_five_to_seventy_nine_years_old - The proportion of residents aged sixty five to seventy nine years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_twenty_five_to_sixty_four_years_old - The proportion of residents aged twenty five to sixty four years old. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_under_one_year_old - The proportion of residents under one year of age. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_white - The proportion of residents who identify themselves as white. From the US Census and the CGIAR Consortium for Spatial Information .
- us_population_white_not_hispanic - The proportion of residents who didn't identify as hispanic or latino, just white alone From the US Census and the CGIAR Consortium for Spatial Information .
- us_sample_area - The total area of the grid cell US Census samples were calculated on. From the US Census and the CGIAR Consortium for Spatial Information .
TwoFishes Geocoder
The open-source city-level TwoFishes geocoder written by David Blackman at Foursquare is included in this package. It's used as part of the Google-style geocoder for non-street addresses, but you can access more advanced features through the /twofishes endpoint. The full API is documented at twofishes.net, and all methods should work as described, but with /twofishes added to the start of the URL. Here's a simple example, demonstrating how the geocoder recognizes native-language cities worldwide and can separate out non-geographic terms:
curl "http://www.datasciencetoolkit.org/twofishes?query=pizza+%D8%A7%D9%84%D9%82%D8%A7%D9%87%D8%B1%D8%A9"
{"interpretations":[{"what":"pizza","where":"القاهرة",
"feature":{"cc":"EG","geometry":{"center":{"lat":30.06263,"lng":31.24967},
"bounds":{"ne":{"lat":30.1480960846,"lng":31.3563537598},
"sw":{"lat":29.9635601044,"lng":31.1625480652}}},
"name":"Cairo","displayName":"Cairo, EG","woeType":7,
"ids":[{"source":"geonameid","id":"360630"}],
"names":[{"name":"Cairo","lang":"en","flags":[16,1]},
{"name":"Cairo","lang":"en","flags":[16]}],"highlightedName":"<b>القاهرة</b>, EG",
"matchedName":"القاهرة, EG","id":"geonameid:360630","attributes":{
"adm0cap":1,"scalerank":0,"labelrank":3,"natscale":600,"population":7734614},
"longId":"72057594038288566"},"scores":{}}]}
Setting up your own server
You can get started using the "http://www.datasciencetoolkit.org/" server, but for intensive use or to run behind a firewall, you'll probably want to create your own machine.
The simplest way to create a server is to grab a virtual machine. This whole server is available ready-to-go as either a Vagrant VM or Amazon EC2 Image.
For Amazon, find the AMI for your region from the list below, e.g. ami-9386d1fa for US-East-1 (see here for the details of tracking down an image).
| US East (N. Virginia) | ami-9386d1fa |
| US West (Oregon) | ami-02be2032 |
| US West (N. California) | ami-000a3e45 |
| EU (Ireland) | ami-70b95f07 |
| Asia Pacific (Singapore) | ami-0a317b58 |
| Asia Pacific (Tokyo) | ami-e11886e0 |
| Asia Pacific (Sydney) | ami-831b86b9 |
| South America (São Paulo) | ami-c15dfadc |
Start a new instance from this image (for example with ec2-run-instances ami-9386d1fa -t m1.large -z us-east-1d), wait a couple of minutes for the machine to boot up, and then paste the public DNS name of the instance into your browser. You should see the normal home page of this site. You can test that it's working by pasting text into the main input. You can then just change your code base URL to that DNS name, and start using the API from your own server immediately. If you don't, check to make sure that your security group rules allow you to access port 80. Note: due to the memory requirements of some DSTK components, the AMI may not function properly on instances smaller than an m1.large.
Vagrant is a free and easy way to run VMs on your local machine. Once you've set up the base software, you can run
vagrant box add dstk http://where.jetpac.com.s3.amazonaws.com/dstk_0.51.box
to download the DSTK image. The VM is almost 24GB, because of the large amount of geographical data included locally, so you'll need a good connection. You may want to try this BitTorrent if the standard HTTP download is too slow. Once you have the image, create a new directory and run
vagrant init dstk
vagrant up
and you should have a local copy of the toolkit accessible at http://localhost:8080. vagrant ssh will give you shell access, or the username and password are both 'vagrant' if you need to log in through VirtualBox's GUI.
If you want to roll your own server from source on an in-house machine, or on another hosting provider, docs/ec2setup.txt in the github repository contains instructions on the exact steps I took to create that image starting from a clean Ubuntu 12.04 installation. You can also download a VMware-compatible .ova image.